📦[Review] DeepSpeed-MoE
[논문 리뷰] 강동규 Reviewed by Kade Kang (devkade12@gmail.com) Reviewed:: 13, 2024
The Purpose of This Study
GPT가 나오고 지난 3년간 성능증가를 위해 LLM 들의 파라미터 크기가 매우 증가했다. 하지만 모델 크기를 키우는 것은 computing cost 로 인해 점점 더 어려워지고 있다. 예를 들어, 2021년 11월 Megatron-Turing NLG 530B Model의 경우 2000개의 A100 GPU를 가지고도 훈련하는데 3달의 시간이 걸렸다.
따라서, 다음의 질문을 던지게 된다.
Computing cost를 증가시키지 않고 유의미한 향상을 이뤄내는 방법은 없을까? 혹은, 3~5배의 더 적은 비용으로 유사한 성능을 낼 수 있는 방법은 없을까?
⇒ Mixture-of-Experts(MoE)
Lit. Review
What is MoE?
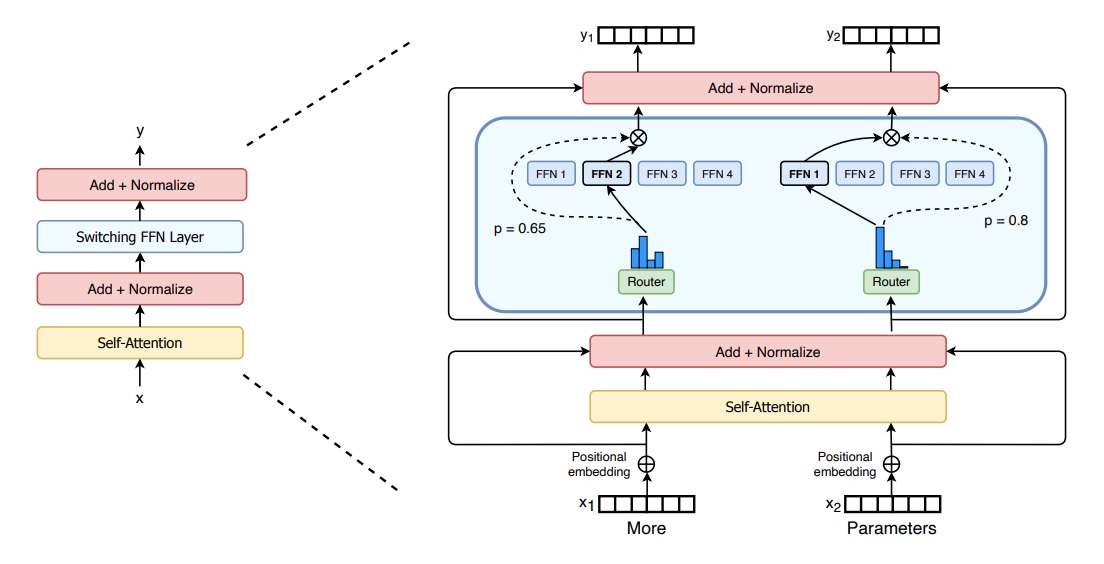 Reference : Switch Transformer
Reference : Switch Transformer
위 그림은 Switch transformer 의 구조를 나타낸다. Mixture-of-Experts 는 위 구조와 같이 여러 개의 전문가 FFN을 사용하여 각 특징에 맞는 FFN을 사용하여 더 좋은 성능을 이끌어 낸다. 하지만 이런 MoE도 몇 가지 문제를 지닌다.
- Limited Scope: NLP에서 MoE 기반 모델의 활용 범위가 encoder-decoder 구조, Seq2seq 작업 등으로 제한된다.(메모리 문제로 인해 Auto-Regressive 모델에서 사용하기 어려움)
- Massive Memory Requirements: 기존 Dense 모델보다 상당히 많은 수의 파라미터를 필요로하고 이는 더 낮은 파라미터 효율을 보인다.
- Limited Inference Performance: 메모리 사용량으로 인해 추론 속도도 떨어진다.
Large Scale Dense NLP Models
- Hundreds of millions of parameters
- BERT, XLNet, RoBERTa, ALBERT, and GPT, etc.
- Billions to dozens of billions models
- GPT-2, TuringNLG, Megatron-LM, T5, etc.
- Extra-Large Model
- GPT-3, Megatron-Turing NLG 530B model
Methods
DeepSpeed-MoE for NLG: Reducing the Training Cost of Language Models by 5 Times
Natural Language Generation(NLG)는 다양한 분야에 대해서 확실한 답을 제공해준다. 활용성이 뛰어나기 때문에 NLG의 성능을 올리는 것이 중요한 관심사였고, DeepSpeed-MoE 의 경우 같은 훈련 비용을 가지고도 더 좋은 성능을 내도록 향상시켰다.
MoE based NLG Model Architecture
- MoE based NLG
- 350M (24layers, 1024 hidden size, 16 attention heads)
- 1.3B (24 layers, 2048 hidden size, 16 attention heads)
- 6.7B (32 layers, 4096 hidden size, 32 attention heads)
- MoE-128 : 각 FFN마다 128개의 전문가를 적용한 것.
- Transformer 기반 NLG 모델인 GPT를 연구해 위 3가지 모델을 선정
- 실제로 순전파, 역전파 시에 활성화되는 파라미터의 수는 MoE를 적용했을 때와 적용하지 않았을 때가 동일하다. (e.g. 1.3B 모델의 경우 1.3B와 1.3B+MoE-128의 토큰당 활성화되는 파라미터 수는 1.3B 이다.)
- 각 토큰에 대해 gating function을 통해서 각 전문가로 전달한다.
Training and Evaluation Setting
 Reference :
Reference : - Ampere A100 GPU 128개 사용
- Data Parallel + Expert Parallel 사용
- 데이터 : MT-NLG 모델 훈련 데이터 사용
MoE Leads to Better Quality for NLG Models
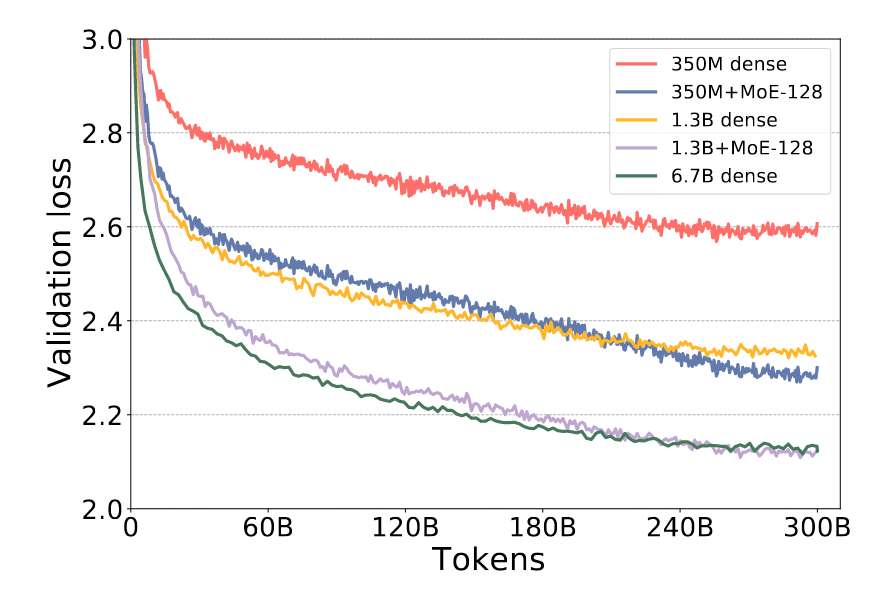 Reference :
Reference : - MoE를 적용한 Loss가 Dense 모델보다 더 좋은 성능을 보이고 있음을 나타낸다.
- 6.7B Dense 모델의 크기보다 5배 적은 1.3B+MoE-128이 비슷한 성능을 보임을 확인할 수 있다.
- 4~5배를 절감하여 처리량 증가, 훈련 시간 및 비용 절감으로 전환할 수 있다.
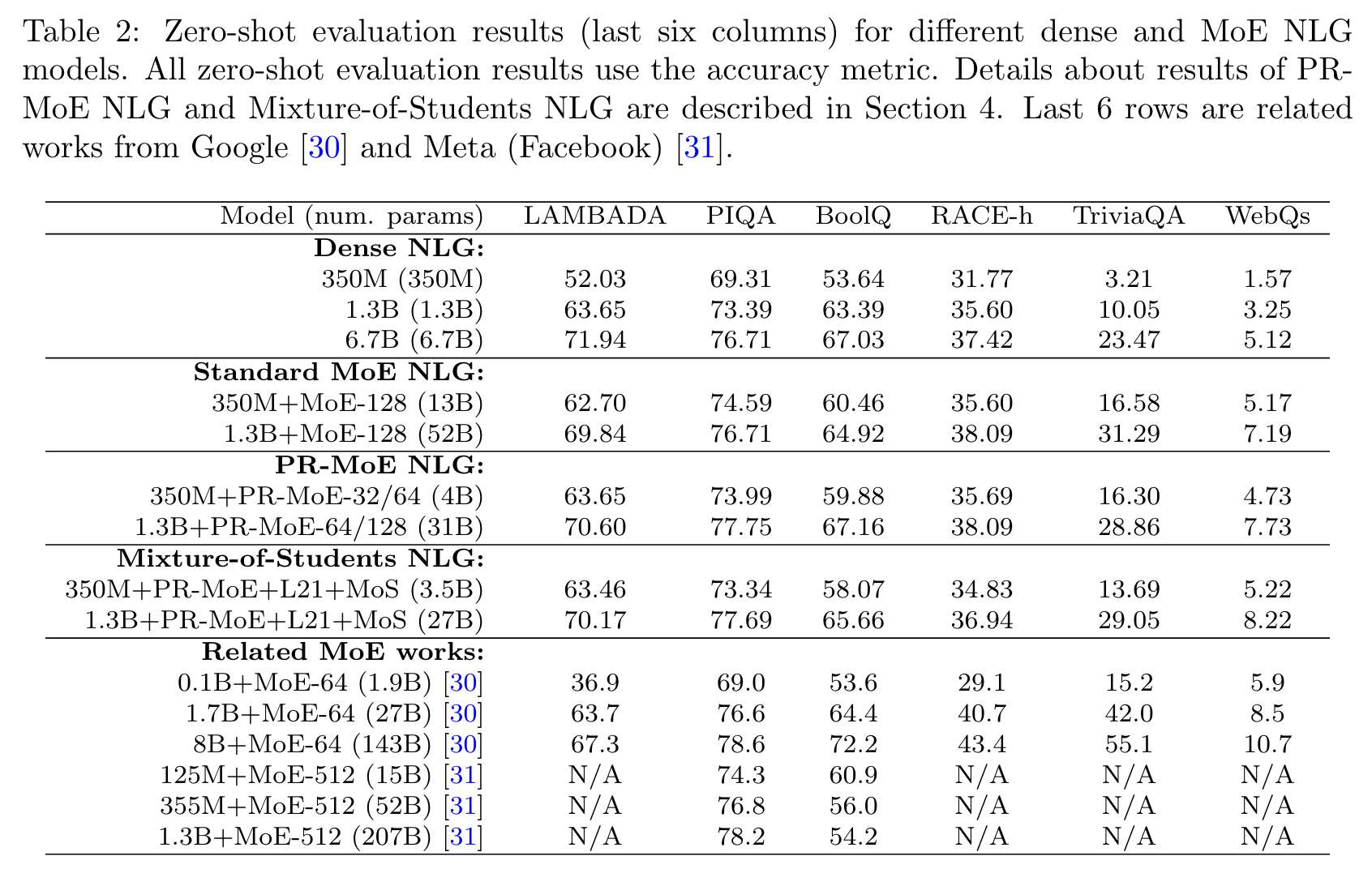 Reference :
Reference : - Zero-Shot 평가를 진행했을 때에도 Dense에 비해 4~5배 절감할 수 있음을 보인다.#Zero-Shot
PR-MoE and MoS: Reducing the Model Size and Improving Parameter Efficiency
Table 1 의 각 모델별 파라미터의 수를 확인해보면 MoE를 적용한 모델의 파라미터 수가 Dense 모델에 비해 약 8배 정도 되는 파라미터 수를 갖는다. MoE 모델은 더 많은 메모리를 필요로 하고, 이는 다음의 문제를 갖는다.
- 모델의 학습 시 많은 메모리를 요구
- 추론에서 모델의 가중치를 읽는 데 소비되는 메모리 대역폭이 주요한 성능 병목 원인이다. 즉, MoE를 사용하는 경우 많은 파라미터 수로 인해 추론 속도가 느려진다.
⇒ 전체 모델 크기를 최대 3배까지 줄일 수 있는 PR-MoE + Distillation을 활용한 Mixture-of-Student(MoS) 를 제시했다.#Distillation
PR-MoE: Pyramid-Residual-MoE for Smaller Model Size and Fast Inference
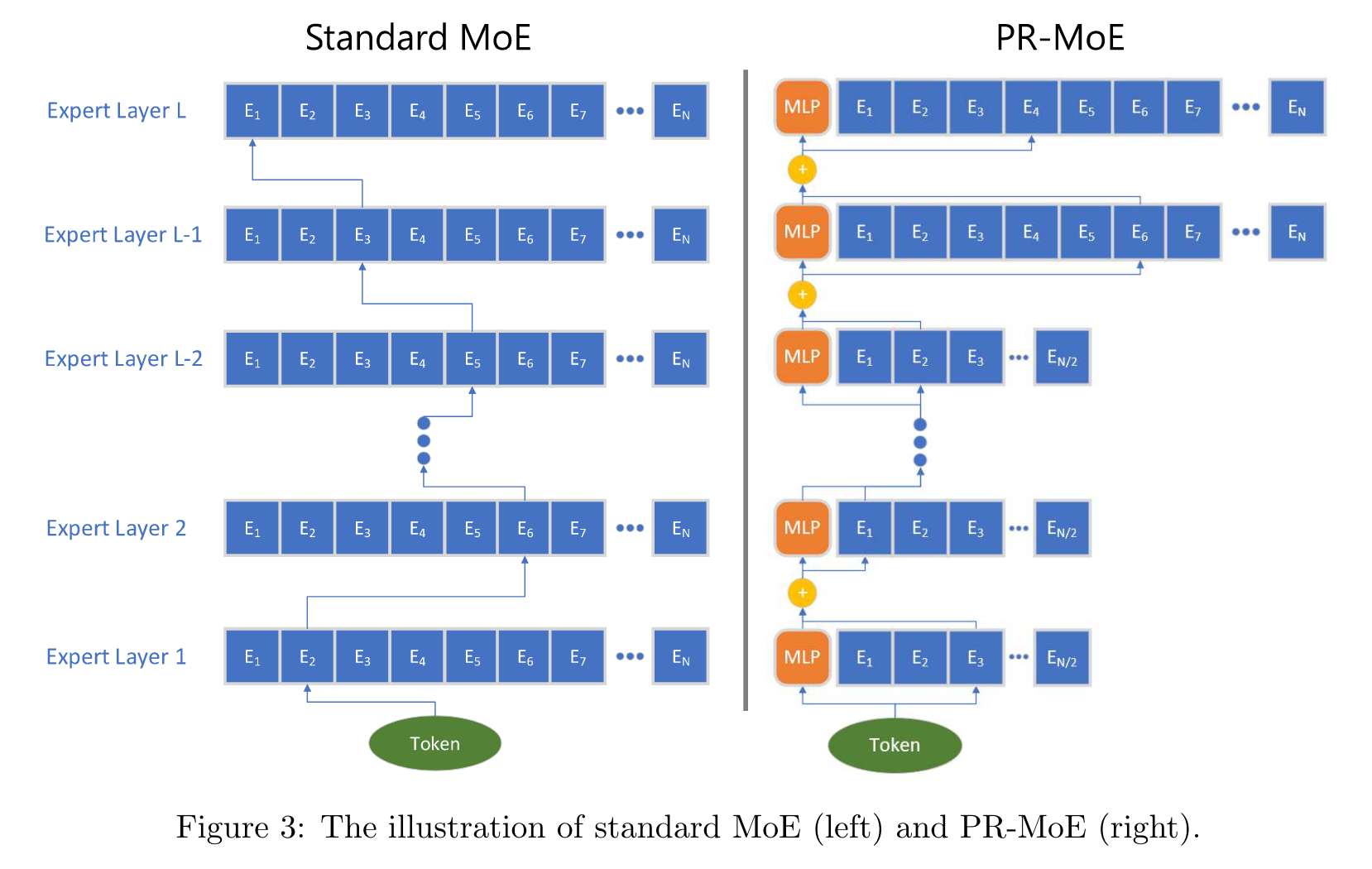 Reference :
Reference : - 모델의 크기를 줄이면서 성능은 낼 수 있는 방법으로 위 그림의 구조와 같은 PR-MoE 구조를 제시했다.
- PR-MoE 는 마지막 몇 개의 계층에서 더 많은 전문가를 사용하고, MLP 모듈과 MoE 모듈을 동시에 사용하는 구조를 갖는다.
- PR-MoE 구조는 아래의 과정을 통해 제시됐다.
Phenomenon1
Standard MoE 구조는 각 MoE 계층마다의 전문가의 수와 구조가 동일하다. 이 동일한 구조를 줄일 수는 없을까? ⇒ CV에서는 얕은 레이어에서 일반적인 특징을 학습하고 깊은 레이어에서 보다 구체적이고 데이터에 기반한 표현을 학습한다. 이런 특징을 이용해 미세 조정시 얕은 레이어는 고정하고 깊은 레이어만 미세조정하는 방식을 사용했다. 이를 동일하게 적용해보고자 아래 2가지를 비교했다.
- First-Half MoE(얕은 부분에서 중간 부분까지 MoE 적용)과
- Second-Half MoE(중간 부분에서 끝 부분까지 MoE 적용)를 비교했다.
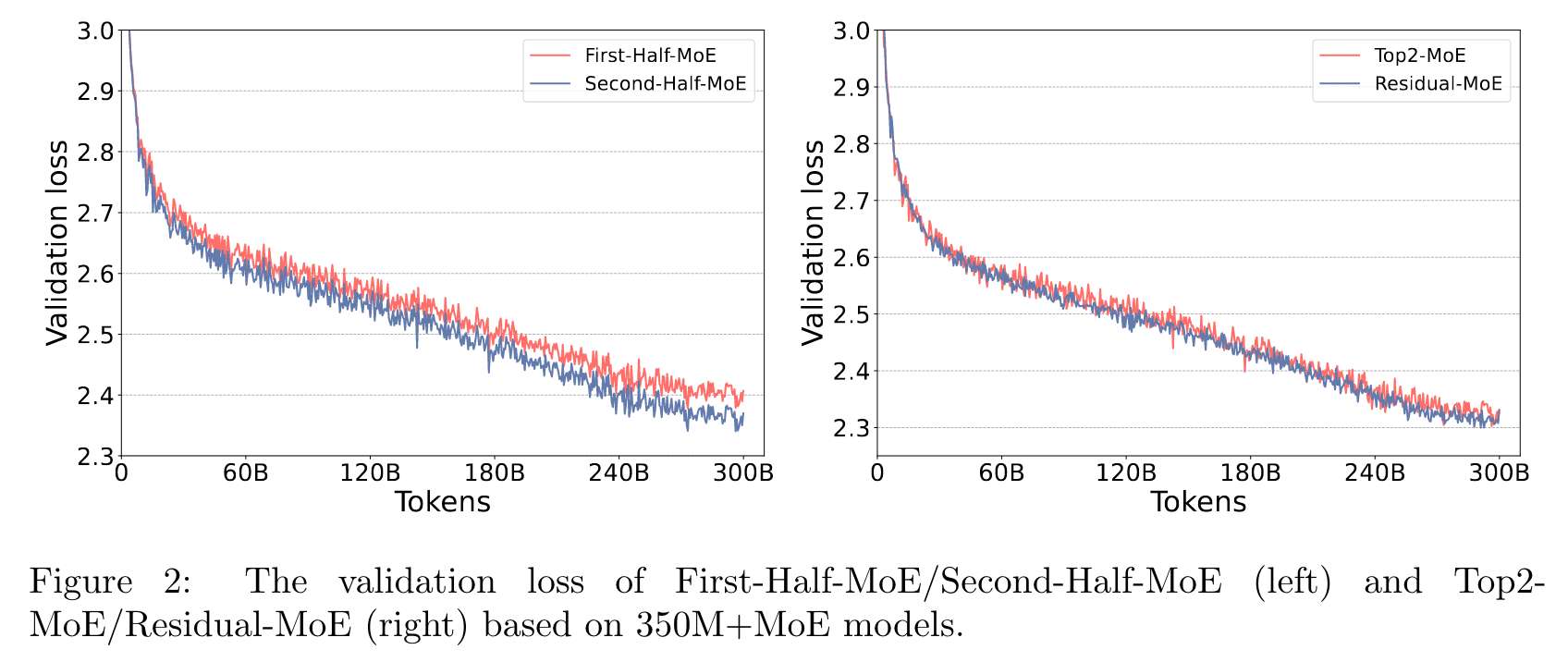 Reference :
Reference : 위 Figure 2의 왼쪽을 보면 Second-Half MoE가 더 좋은 성능을 보인다. 즉, 끝 부분에 MoE를 적용할 경우 전문가의 효과가 더 뛰어남을 알 수 있다.
Phenomenon2
MoE 모델의 일반화 성능을 향상시키는 방법은 무엇이 있을까?
- 전문가 용량(각 토큰이 거치는 전문가 수)를 동일하게 유지하면서 전문가 수를 늘리는 방법
- 전문가 수를 유지하면서 전문가 용량을 늘리는 방법
1번의 경우 전문가 수가 많아지기에 학습에 필요한 메모리 비용이 증가한다. 2번의 경우 용량이 커지면서 통신량도 늘어나기 때문에 학습, 추론에 병목이 발생할 수 있다.
학습, 추론 효율성을 유지하면서 일반화 성능을 향상시키는 방법은 없을까? 전문가의 용량을 왜 늘리고자 할까? 두 명의 전문가가 판단한다면 더 일반화된 정보를 전달할 수 있기 때문이다. 두 명의 전문가가 판단을 한다는 것은 추가 전문가가 첫 번째 전문가에게 첨언을 통해 판단의 수정을 할 수 있다는 것을 의미한다. ⇒ 그렇다면 라우팅을 통해 첫 번째 전문가를 매 토큰마다 수정해야 하는가? 혹은 한 명의 전문가를 고정으로 해두고 첨언할 수 있는 전문가를 두어야 하는가?
이를 확인하기 위해 아래 2가지를 비교했다.
- 용량을 2배로 늘리는 방법(Top2-MoE: 2명의 전문가에게 전달, 출력을 합산)
- 한 전문가로 고정하고 토큰마다 두 번째 전문가로 변경하는 방법(Residual-MoE: MLP 모듈로 고정, MoE 모듈을 통해 전문가 뽑아 합산)
Figure 2의 오른쪽이 해당 실험의 결과이다. Top2-MoE 와 Residual-MoE 가 비슷한 성능을 보임을 알 수 있다. Residual-MoE 의 경우 Top-1 gating과 동일한 양의 통신량으로 레이어당 2개의 전문가를 사용하는 이점을 얻을 수 있다. 실험에서는 Residual-MoE 의 속도가 Top2-MoE 보다 10% 이상 빠르다고 한다.
Efficient Training an MoE Model
각 MoE 모델을 효율적으로 훈련하기 위해서는 각 전문가에 순전파로 통과하는 배치 크기가 충분히 커서, 훈련이 잘 되어야 한다. 하지만 전문가의 수가 많아질수록 전문가 하나가 차지할 수 있는 토큰 수가 줄어든다. ⇒ Data Parallel + Expert Parallel 을 통해 해결한다.
전문가 수와 병렬화 할 수 있는 자원이 동일하다면 효율적으로 훈련할 수 있겠지만, 그렇지 않은 경우가 더 많다. 즉, 다음의 문제가 발생한다.
- 전문가 병렬화를 최소 전문가 수로 설정한다면 GPU당 다수의 전문가가 있을 것이고, 낮은 효율을 내게 된다.
- 전문가 병렬화를 모델에서 가장 많은 수의 전문가로 설정하면 load balancing 문제로 인해 효율성이 제한된다.
이를 해결하기 위해 DeepSpeed-MoE를 이용해 유연한 병렬 처리 설계를 개발했다. 정확한 병렬 처리는 코드를 분석해봐야 할 것 같다.
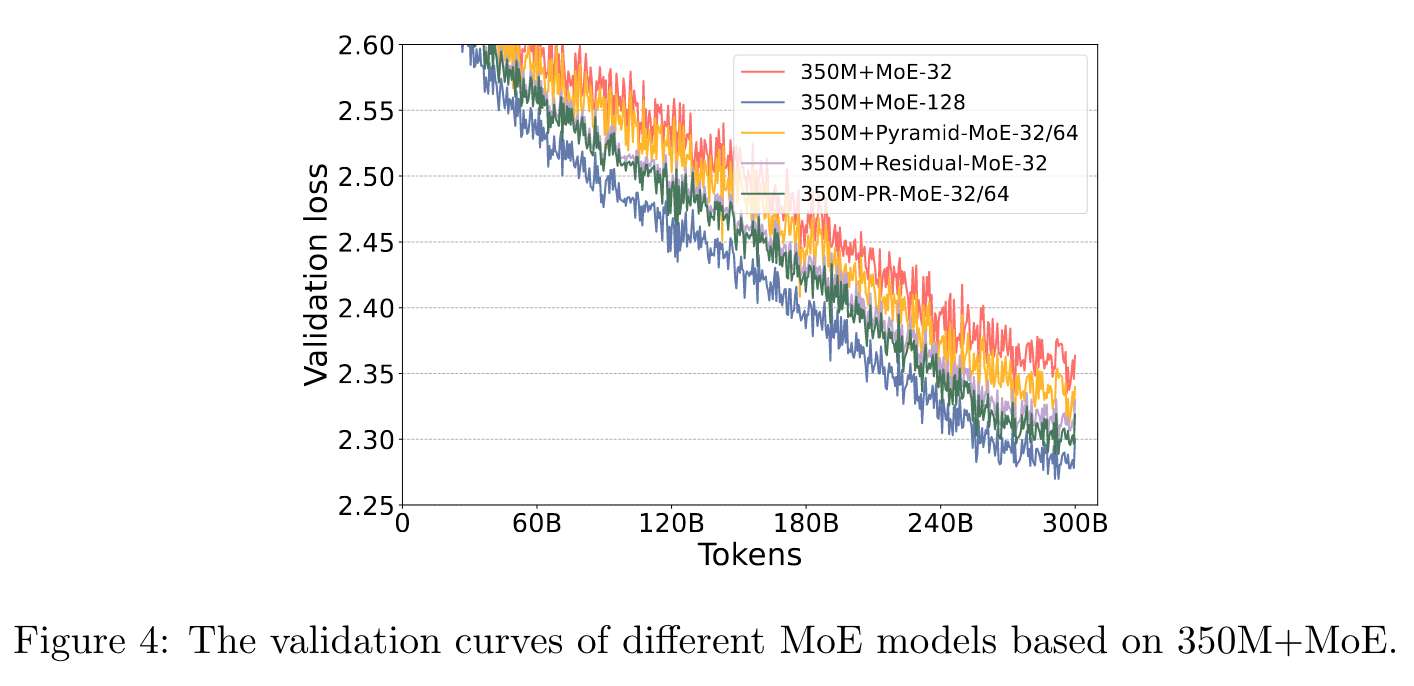
Ablation Study of Different MoE Architectures
Mixture-of-Students: Distillation for Even Smaller Model Size and Faster Inference
기존에 LLM을 작업별 작은 모델로 증류하는 데 KD를 적용한 연구가 있었으나, 작은 트렌스포머, 인코더 기반 LM 모델만을 고려했다. 해당 논문에서는 KD로 사전 학습된 작은 MoE 모델에 대해 여러 작업에서 zero-shot 평가와 같은 유사한 성능에 도달할 수 있고, 더 가볍고 빠른 모델을 생성할 수 있음을 보였다.
Architecture Choice and Optimization Objective
- 교사 MoE 모델을 훈련한다.
- 교사 모델에서 각 전문가의 깊이를 줄여 학생을 얻는다.
- 해당 학생 모델을 MoS라 부른다.
- MoS는 아래 KD Loss를 통해 교사를 모방하도록 한다.
: 예측과 주어진 Hard Label 사이 교차 엔트로피 손실 : 예측과 교사의 Soft Label 사이 KL Divergence 손실
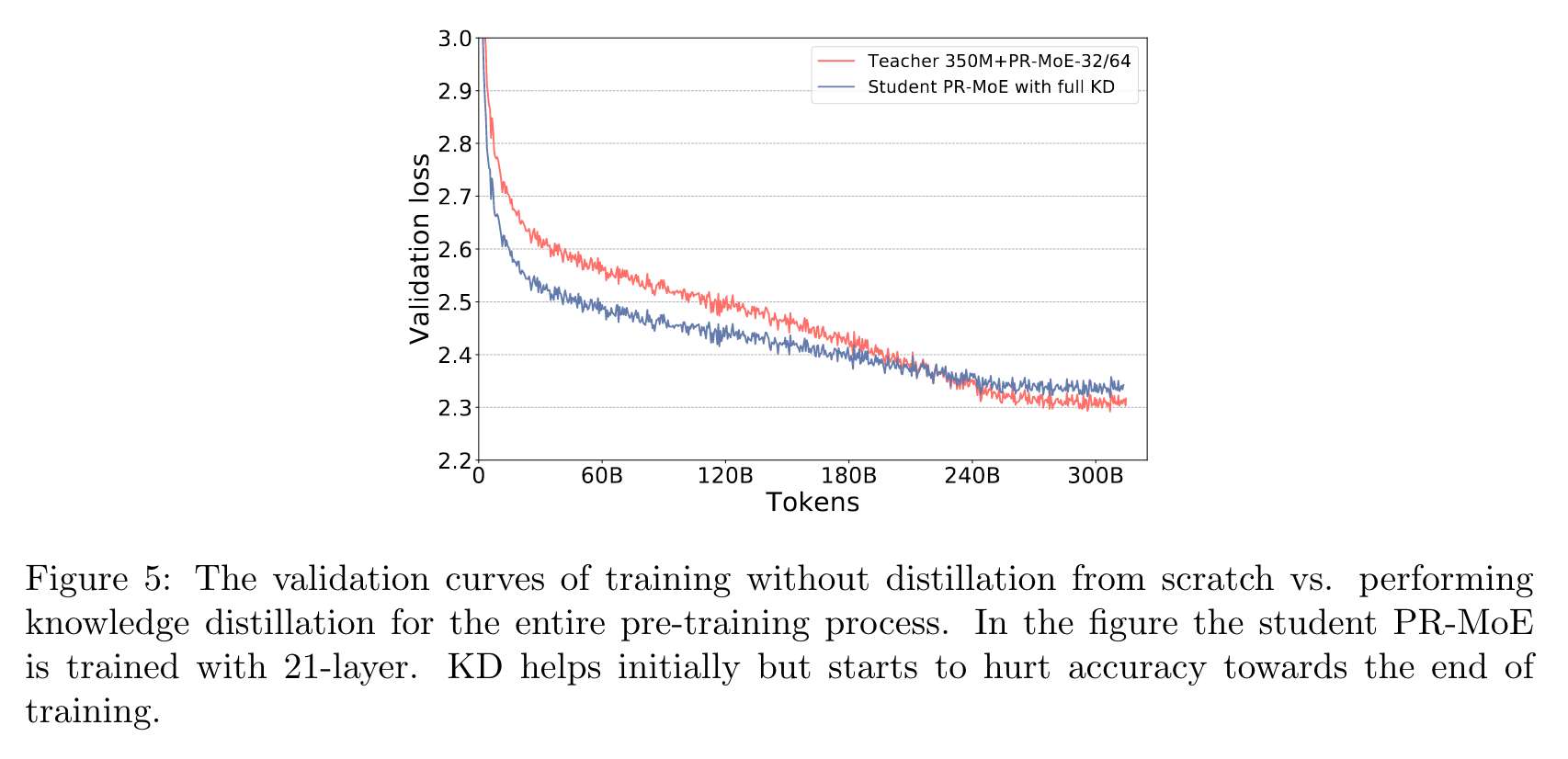
-
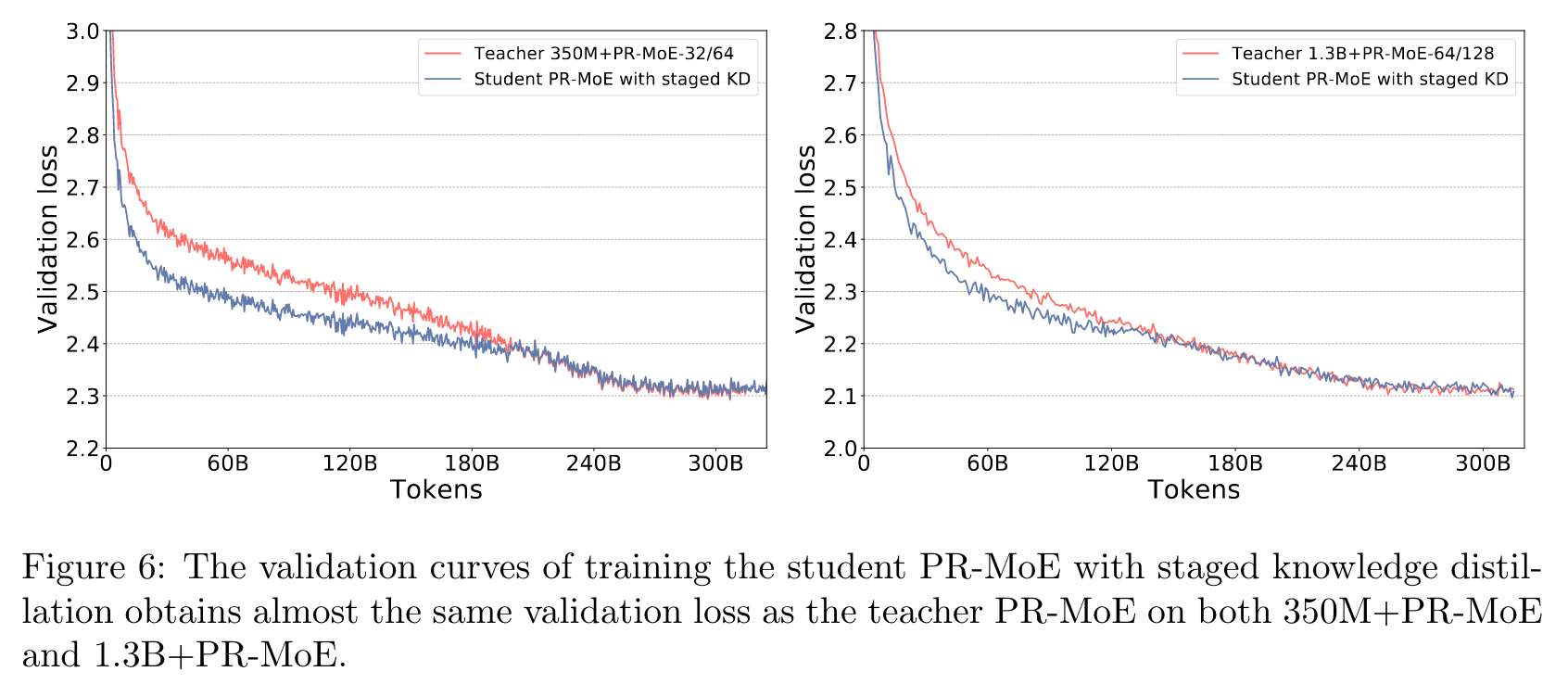
처음에는 정확도를 향상시키나, 훈련이 끝날수록 정확도가 떨어진다.
-
학생 모델이 충분한 용량을 가지지 못했기 때문에 발생할 수 있다.
-
훈련의 끝부분에서 교차 엔트로피 손실을 희생시키면서 KL Divergence 손실을 줄이고자 할 수 있기 때문에 점차 KL Divergence 손실의 영향을 줄인다. 이때의 결과는 아래와 같다.
DeepSpeed-MoE Inference
추후 정리